ŚNIADANIE Z KORPUSEM (2): Mark Davies
Sierpień był dla mnie dość pracowitym miesiącem, stąd znikoma liczba postów. Pod względem czasu na aktualizacje bloga lepsze perspektywy zdaję się mieć na wrzesień, zatem przyspieszam przegląd ciekawszych zagadnień korpusowych. Dziś wezmę pod lupę korpusy Marka Daviesa.


Davies jest profesorem na Brigham
Young University, a także twórcą
korpusów językowych które można znaleźć tutaj. Jak głosi informacja w nagłówku,
mamy tu do dyspozycji siedem różnych korpusów. Dwa z nich poświęcone są językom
innym niż angielski. Corpus of Contemporary American
English (COCA) to zasób na którym zaprezentuję większość omawianych kwestii. Jest to
korpus współczesnej amerykańskiej angielszczyzny, podzielonej na kilka
kategorii (a więc pochodzącej z różnych źródeł): prasa, fikcja literacka itd. Ciekawym podkorpusem
jest Corpus of American Soap Operas, który
oferuje nam wgląd w transkrypcje amerykańskich oper mydlanych celem dostarczenia szukającym nieformalnego, kolokwialnego materiału językowego, o czym jeszcze słówko na koniec, kiedy zobaczymy, jak wysuwać pierwsze wnioski z obserwacji danych korpusowych. Rewelacyjne prezentuje się COHA, a więc Corpus of Historical
American English, gdzie możemy śledzić zmiany w leksyce i gramatyce
angielskiej, zebranych ze źródeł na przestrzeni lat 1810 - 2009! O tym jak to
robić również w jednym z kolejnych wpisów. Dziś zapoznamy się z przeglądarką
korpusową, sposobem wprowadzania informacji oraz zobaczymy, jak interpretować prostsze wyniki. Jak już wspomniałem,
wykorzystamy do tego korpus COCA, a także w mniejszym stopniu COHA. Udajmy się
więc pod adres: http://corpus.byu.edu/coca/.
Polecam założenie konta na
portalu. Jest ono darmowe, a daje nam zdecydowanie więcej możliwości jako
użytkownikom. Przede wszystkim mamy wtedy większą możliwość zapytań w
przeglądarce, a więc 100* ( dla porównania: gdy użytkownikami nie jesteśmy mamy
ich tylko pięć na dobę). Rejestracja nie jest skomplikowana, ale musimy w niej np.
określić nasz status badawczy (czy jesteśmy zawodowymi językoznawcami, czy
tylko poszukiwaczami ciekawostek). Po utworzeniu konta możemy rozpocząć pracę z
korpusem.
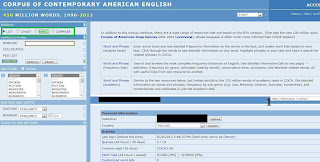
Po wpisaniu powyższego adresu
zobaczymy ten interfejs:

W swoim wpisie z oczywistych
względów zajmę się wybranymi funkcjami, o wszystkich można bowiem znaleźć
informację klikając na (1), gdzie znajdziemy m.in. przewodnik po funkcjach, przykładowe zapytania
etc. Niestety (choć chyba jednak stety:)), całość jest w języku angielskim.
Nasz pasek zadań znajduje się po
lewej stronie. Szukane słówko/frazę wpisujemy w okienko WORD(S) a następnie
klikamy SEARCH. Zaznaczona domyślnie opcja LIST (patrz: zielona ramka) wyświetla konkordancję jedną
pod drugą (po kliknięciu na słówko, bądź wynik wyszukiwania w oknie głównym po
prawej stronie, co pokazuję na obrazkach). Okno zostało tak zaprojektowane, iż
poszczególne sekcje „chowają” się gdy najedziemy kursorem na inne. Najeżdżajmy
więc na wszystko po kolei, aby wyczuć chowające się elementy, albo gdy coś
zgubimy. Gdy zaznaczymy opcję CHART i klikniemy SEARCH,
zobaczymy występowanie danego słowa (w tym przypadku attend) z wyróżnieniem na
lata oraz kategorie:

Jest to szczególnie interesujące, gdy ciekawi nas
zachowanie jakiegoś słowa na przestrzeni lat, albo jego występowanie w
gatunkach językowych. Najazd kursorem na poszczególną kolumnę powoduje
wyświetlenie kilku danych statystycznych w małym okienku po prawej stronie (zielona ramka).
Widzimy tam rozmiar sekcji (SIZE, w mln słów), liczbę znalezień (#TOKENS), oraz
zależność statystyczną (liczba znalezień dzielona przez rozmiar, mnożona przez
sto, lub tysiąc, w zależności od sposobu prezentacji danych, lub potrzeby ich
porównania), dla osób zainteresowanych analizą ilościową. Opcja KWIC przydaje
się, jak widać, kiedy chcemy zobaczyć jakie otoczenie występuje wokół interesującego
nas słowa, co ma szerokie zastosowanie wobec różnych zainteresowań badaczy
języka, bądź uczących się go (wpiszmy however, lub though, które zdaje się być
kłopotliwe dla wielu osób uczących się angielskiego). Zaznaczenie ostatniej
opcji powoduje rzecz jasna zapytanie porównawcze i jest oczywiście szalenie
interesujące, zwłaszcza pod względem analizy ilościowej. Przeglądarka od razu
zasypuje nas lawiną danych statystycznych, które mogą okazać się bardzo
ciekawe, a nieraz i zaskakujące. Najlepiej od razu wspomnieć tu o opcji
COLLOCATES widocznej zaraz pod okienkiem WORD(S). Zaznaczenie tej opcji
(poprzez kliknięcie na nią) powoduje wyszukanie słów współwystępujących z tym(i)
przez nas badanym(i). Z okienek obok wybieramy liczbę słów „graniczących” z
naszym zapytaniem (odpowiednio po jednej i po drugiej stronie, czyli za nim i
przed nim). Jeśli wpiszemy słowa stupid oraz silly oraz wybierzemy odpowiednio
numerki 0 oraz 1 otrzymamy porównanie tych dwóch przymiotników pod względem ich
występowania w korpusie wraz z bezpośrednio następującym po nim elementem
leksykalnym. Wynik:

mówi
nam na przykład iż:
·
w
korpusie znajduje się więcej próbek stupid, niż silly (1.88 do 0.53;
szczegółowe wyjaśnienie danych statystycznych znajduje się TUTAJ http://corpus.byu.edu/coca/help/display_words_compare_e.asp?h=y
·
słówka
takie jak horse, idiot, policy, albo decisions występują niemal wyłącznie z
przymiotnikiem stupid. Metoda korpusowa pozwala więc określać kolokacje danych
słów, a więc również ich stopień
synonimiczności, a zatem i profil
tej synonimiczności.
Wadą opcji COMPARE jest fakt, iż
nie można porównać dwóch wyrażeń składających się z różnej liczby elementów
(odpada więc porównywanie rzeczy typu cause z bring about etc.).
Kolejną wartą uwagi rzeczą jest
opcja dostępna poniżej, w pasku CLICK TO SEE OPTIONS. W okienku GROUP BY
głównym podziałem jest ten na słowa i lematy (words i lemmas). Words są w tym
przypadku daną leksykalną formą tego słowa, czyli np.: write i tylko write.
Jeśli interesują nas inne formy (tj. odmienione), wybieramy lemma. Wtedy nasz
wynik będzie bogatszy o writes, writed itd. (klikamy na pierwszy wynik „od góry”).
Drobne znaczki zapytania obok
każdej z funkcji odeślą nas do szczegółów korzystania z nich. Niniejszy post ma
posłużyć jedynie pokazaniu podstawowych kroków jakie możemy poczynić w
korpusach Daviesa. W następnym zaprezentuję ciekawe, usprawniające nasze
poszukiwania lecz też bardziej skomplikowane metody wprowadzania danych do
przeglądarki, co przydaje się, na przykład w poszukiwaniu synonimów.
cdn.
P.S.
A, i zamieszczam próbkę danych z korpusów: COCA, BNC, oraz Corpus of American Soap Operas. Jakie są Wasze spostrzeżenia nt. danych liczbowych?:)
query
|
example
|
SOAP
|
COCA
|
|
. you
[vv*] me ?
|
. You heard me? (=subject
ellipsis)
|
|||
, ok|okay
?
|
we're
leaving now, OK?
|
|||
, right ?
|
you're
pretty tired, right?
|
|||
I'm good
|
I'm good
|
|||
[be] so
not [ADJ]
|
That is so not possible.
|
|||
I told you
|
I told you to get out of here
|
|||
[do] n't
get it
|
I don't get it -- why do you hate me so much?
|
|||
how can
you
|
How can you even say that?
|
|||
I totally
|
I totally get it now!
|
|||
[screw]
[PRON]
|
I'm not gonna screw it up this time.
|
|||
[freak]
[PRON] out
|
Man, that totally freaked us out !
|
|||
[creep]
[PRON] out
|
He really creeps me out -- he's so gross!
|
|||
my God
|
My God -- she's horrible!
|
|||
. it 's
[ADJ] .
|
. It's sad. She's totally
forgotten him. (=short
phrases)
|
|||
Situational (shows that the soap opera scripts are very oriented to the
"here and now")
|
||||
hand me *
[NOUN]
|
Hand me a
towel.
|
|||
. Get out
|
. Get out before I call the
police!
|
|||
Do n't
leave
|
Don't leave! I need you!
|
|||

Komentarze
Prześlij komentarz